chisme · reflections
behind the scenes of building an AI-powered language quiz generator
overview
Learning a new language has never been easier with the recent explosion in
AI tools. Grammar rules that make no sense? Unsure whether it is a
buongiorno or a bonjour or which countries you offend when
you put croissants on a pizza? Not to worry, your favourite LLM tool can
now be your personal tutor, ready to answer the questions you'd never dare
ask in a classroom full of students.
But what about testing what you've learned? Despite LLMs' ability to generate questions, I find it difficult to hide the answers or get the same level of interactive feedback that traditional quizzes provide. Plain text quizzes just don't deliver the same learning experience.
That’s where chisme comes in.
project goals
With
chisme, I set out to:
• design a modern and engaging interface that uses an LLM behind the scenes to generate quizzes based on the user's language level and interests.
• evaluate how well the LLM's responses align with the given prompts.
technical design
Chisme
is a full-stack project powered by OpenAI's GPT-4o model. The app is fully
hosted on AWS and uses the following architecture:
• backend: flask + gunicorn running on an AWS EC2 instance
• frontend: react + typescript, built with vite for fast iteration
• proxy & routing: nginx handles both static file serving and API proxying.
I used a similar deployment setup in my previous projects — a more detailed overview is available here.
technical notes
• Nginx supports multiple server redirection. Here is a snippet of how I
configured my Nginx.config file:
http {
# additional directives
server {
listen 80;
listen [::]:80;
server_name _;
root /home/YOUR_ROOT_PATH/; # ‹-- sets root path
index index.html; # ‹-- default file types to be served
# additional proxy directives
location /YOUR_API/ { # ‹-- relative to root path
proxy_pass_header Server;
proxy_set_header Host $Http_host;
proxy_redirect off;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Scheme $scheme;
proxy_connect_timeout 10;
proxy_read_timeout 10;
proxy_pass YOUR_API_PATH_ENDPOINT; # ‹-- add flask enpoint
}
location /YOUR_WEBAPP/ {
try_files $uri /YOUR_WEBAPP_DIST/index.html; # ‹-- path to the built files
}
# You can keep adding servers or endpoints by configuring additional location blocks
# Nginx also lets you configure redirection to error handling pages
# error_page 404 /404.html;
# location = /404.html {
# }
}
}
• I used vite for quick and easy setup. The only gotcha when using vite with nginx, is that you need to set the correct base path in vite.config.ts to match your nginx route:
export default defineConfig({
plugins: [react({
include: "**/*.tsx",
})],
base: '/YOUR_PATH/', # ‹-- match to directive in nginx config
server: {
open: true
}
})
• I opted for a single-page dynamic rendering and used the useContext hook for shared state management. By the end of the project, the context grew quite large — in the next version, I'd like to explore using a reducer or state management library for better scalability.
the art of prompt engineering
This project gave me a real taste of the challenges of prompt engineering:
• hallucinations (where the LLM returns incorrect or totally out of context answers) do happen. Handling them consistently is key if you want your app to be production-ready.
• due to these inconsistencies it's very difficult to test an AI-powered endpoint — small wording changes can produce wildly different results.
Let's take a look at some examples where the LLM did not perform despite providing detailed and clear instructions. Here is the prompt that I fed the LLM.
You are a quiz generator for a language learning app. The user is learning {language} at a {level} level. Quiz topics should cover grammar and {", ".join(topic)} Generate a quiz in JSON format only. Do not include explanations or extra text. Do not wrap the JSON in triple backticks or any other formatting. The answer MUST match exactly one of the options. Return EXACTLY in this JSON format: { "questions": [ { "question": "string", "options": [], "answer": "string" } ] }
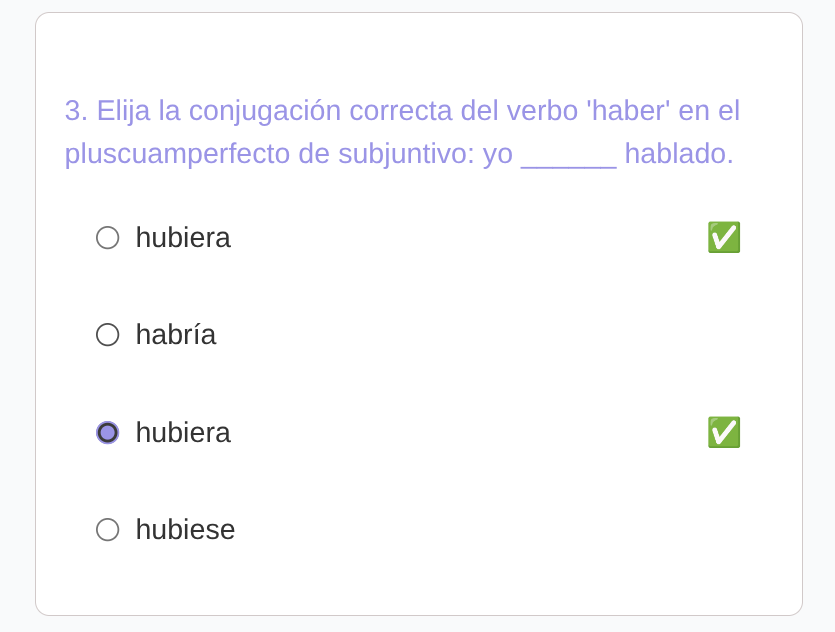
• prompt: the answer must match exactly one of the options
Unfortunately the LLM did not get the memo in this instance and returned
two valid answers.
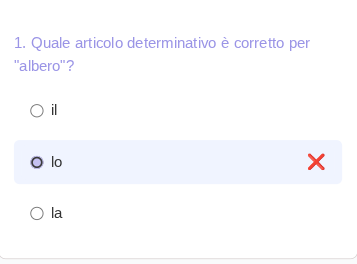
• prompt: the answer must match exactly one of the options
Here the options provided did not include the correct answer.


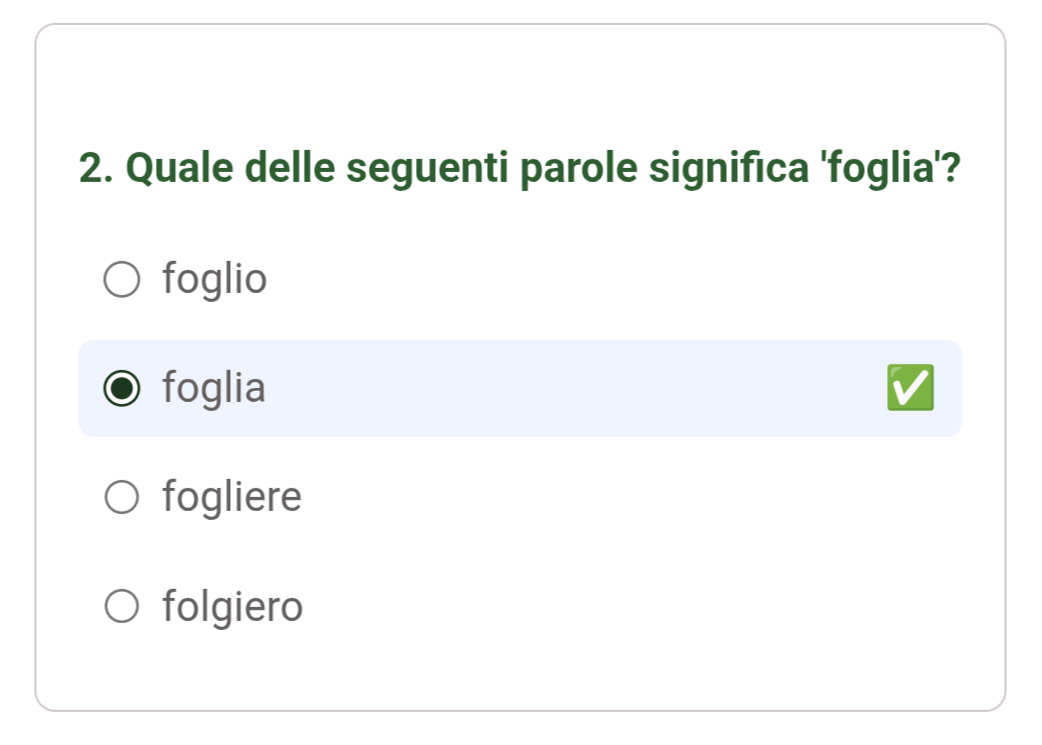
• sometimes the questions don't make a ton of sense
In this instance it's asking for the meaning of leaf and the answer
is...well, leaf.
It is definitely possible to build workarounds to handle these mishaps, however even a slight change in the prompt wording might immediately introduce new errors and instability, possibly requiring a new testing strategy.
These examples highlight the importance of prompt engineering and building systems that are robust enough to handle the uncertainty that inevitably arises when interacting with an LLM.
final thoughts
Building
chisme
was a lot of fun, but the LLM's inability to exactly follow the prompt
100% of the time made it difficult to test. Definitely a great reminder to
always take LLM answers with a grain of salt.
In the next iteration, I would love to explore:
• adding multiple quiz formats (e.g., flashcards or timed challenges)
• introducing user-based personalization or progress tracking
• experimenting with fine-tuned models for more consistent quiz quality.
Overall, building chisme was a great playground for blending AI, frontend interactivity, and backend architecture — and a gentle reminder that curiosity, a dash of skepticism, and a handful of humility will always be key ingredients to keep handy on your learning journey.